机器学习筛选食品生物活性化合物的进展
食品中含有丰富的生物活性化合物,对人体健康起着至关重要的作用。然而,筛选食品生物活性化合物的传统方法成本高、耗时长且劳动密集。机器学习技术为筛选潜在的生物活性化合物提供了一种高效且具有成本效益的方法,但其在食品领域的应用和研究还很有限。
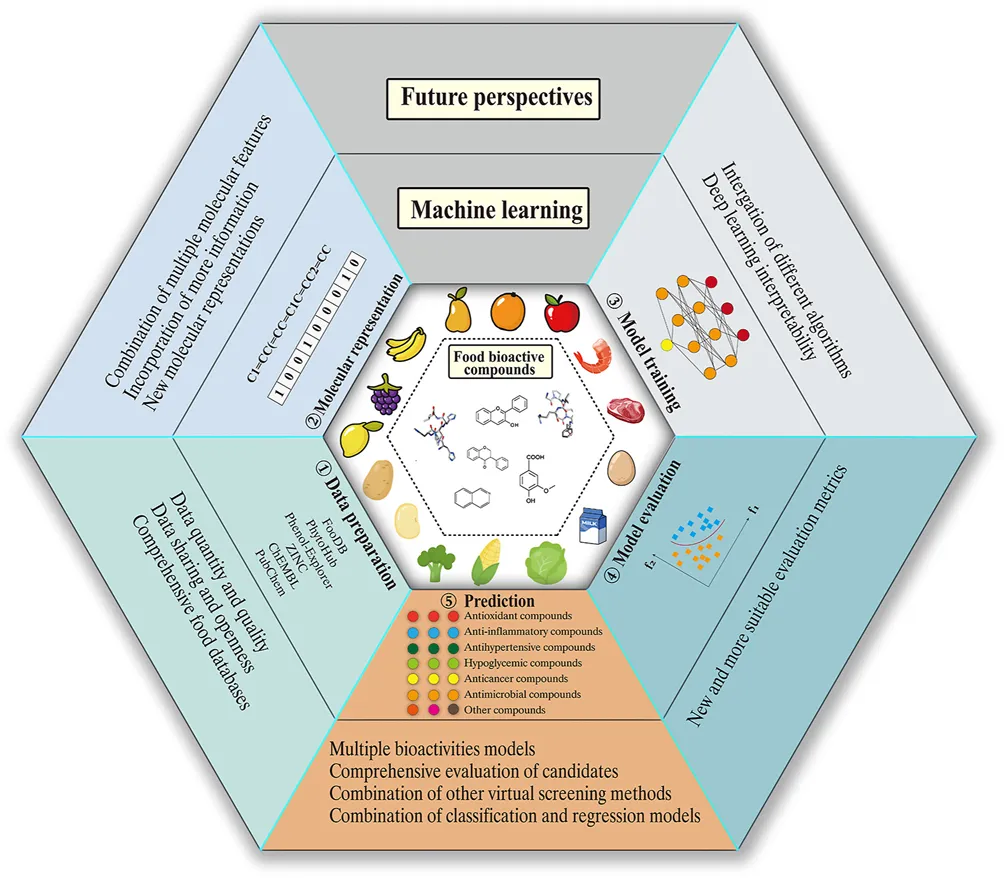
为了促进有效筛选食品生物活性化合物并为研究人员提供有价值的见解,中国农业大学食品学院薛勇副教授等在国际食品Top期刊《Trends in Food Science & Technology》(Q1,中科院1区,IF: 15.3)发表题为“Advances in Machine Learning Screening of Food Bioactive Compounds”的综述性论文,介绍了构建机器学习模型的过程,包括数据准备、分子表示、机器学习算法选择和评估方法,并重点介绍了近年来机器学习在筛选具有不同生物活性的食品生物活性化合物方面的进展。此外,本文还提出了主要的局限性和挑战,并提出了未来的发展方向。
本综述旨在促进机器学习在筛选食品生物活性化合物中的应用,并为研究人员提供有价值的见解,以发现更多促进人类健康的有益化合物。本文概述了开发机器学习模型的一般工作流程,并重点介绍了近年来在筛选具有不同活性的化合物方面取得的研究进展。针对不同生物活性开发机器学习模型时会遇到各种限制和挑战。为确保建立高质量的机器学习模型,必须对建模过程中的每个步骤进行缜密考虑。建议采取以下措施:(1) 建立全面的食品生物活性化合物数据库,开发高质量的数据集和新的分子表示方法,提高深度学习的可解释性,整合不同的机器学习算法,开发更有效、更合适的评价指标;(2) 将机器学习与其他虚拟筛选技术相结合;(3) 将分类模型与回归模型相结合;(4) 建议研究人员不要忽视存在稳定性或溶解性问题的化合物,从多个维度全面评估候选化合物;(5) 开发能够预测多种生物活性的模型。